What Happens When AI Coding Agents Have System Context? Results from 70 Experiments
AI coding agents have changed how software engineers build, and enabled non-engineers to build. I’ve personally been working with them before they were even agents (remember copying and pasting code from ChatGPT into your IDE?)… and they are at the core of operations at gjalla. The agents are getting better at building software, understanding and implementing requirements, debugging, etc., but the industry isn’t talking much about the missing piece. No matter how good the agents are at implementing requirements, they don’t know your customer constraints, they don’t know your integration challenges, they don’t know your architecture rules, the decisions your team made, etc.
At gjalla, coding agents are central to how we build. They’ve dramatically increased our throughput — but they’ve also shifted the burden. We spend less time writing code and more time reviewing it, catching architectural drift, and playing whack-a-mole with issues that a human engineer would have avoided instinctively.
We had a hypothesis: if agents have access to a well-defined expected state, something that captures all of these attributes one layer of abstraction above the code itself, then they should produce better outputs. Not because the model is smarter, but because it’s working with the right guidance.
What do we mean by “better” outputs? We wanted to spend less time reviewing and fixing the code, less time reimplementing, less time debugging or refactoring, and less time apologizing to customers for unintended bugs. Basically - we wanted production ready code without our team taking on the extra burden of fixing a ton of AI-generated code.
Our inspiration came partially from Terraform, which allows infrastructure to be configured declaratively (i.e. you describe the desired state and the tool will converge toward it). In software development, the convergence toward state is a little fuzzier, but the idea is the same and we believe we have the tools to account for the fuzziness.
So we tested it. Here’s the short version of what we found:
The experiment
We ran 168 experiments across 10 production codebases ranging from 240K to 536K lines of code.
Each experiment followed the same structure: implement a real feature twice, once with the coding agent configured to reference expected state via gjalla and once without.
We tested across multiple coding agents (Claude, Codex, Aider, Continue) and feature complexity levels from straightforward additions to cross-cutting architectural changes. We also tested variations where the agent would be provided a full feature spec vs a quick, high-level description of the feature. All agents were directed to work independently and return once complete. No human intervention or correction was provided.
Quality was evaluated across five dimensions: how well the implementation adhered to the designed architecture, how well it adhered to declared rules or constraints, feature completeness, code pattern reuse, and test coverage. A judge agent was tasked with scoring each implementation based on the five dimensions. Deterministic metrics were also collected, such as lines of code added, time and cost of implementation, etc.
What did we find?
TL;DR
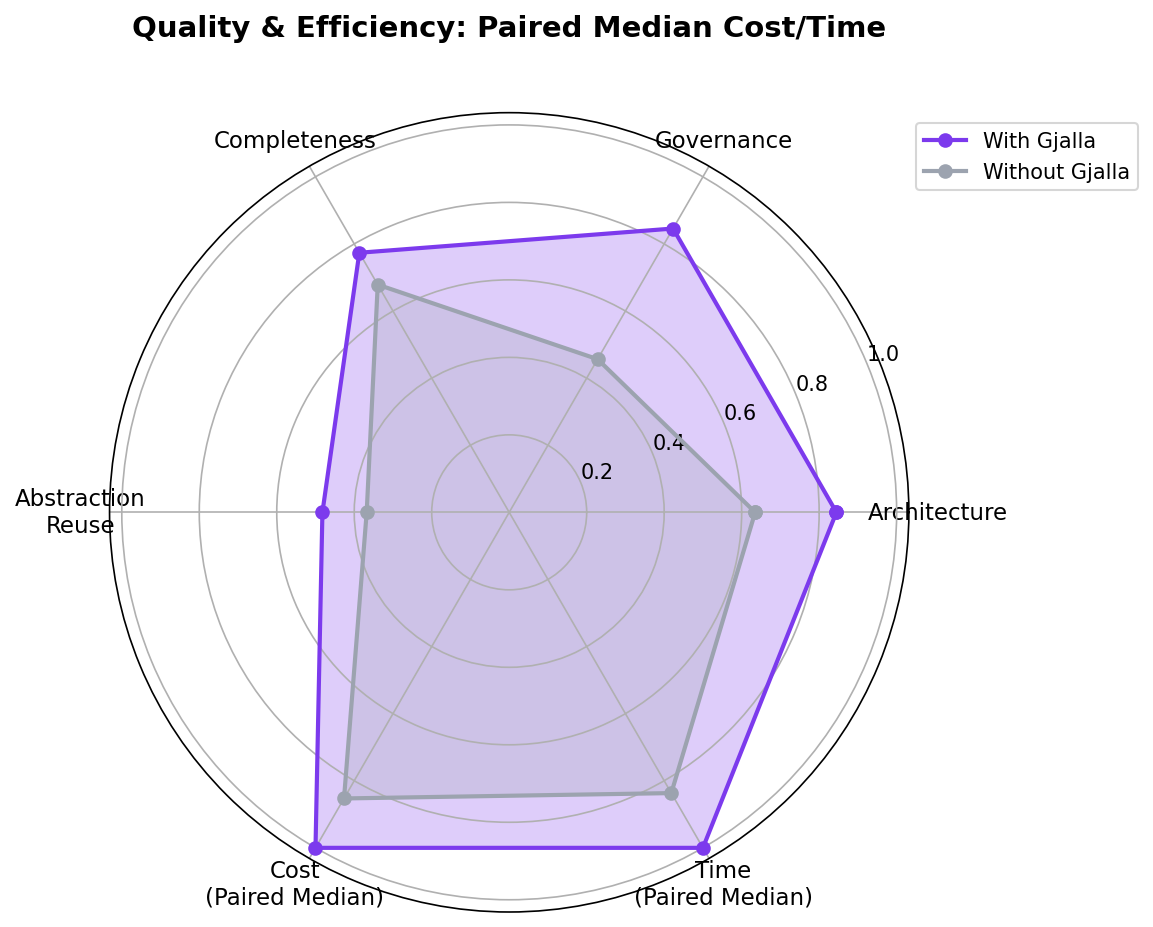
The variants that had access to gjalla resulted in higher quality, faster, and cheaper outputs on average than those without access to gjalla.
The key finding: gjalla decouples quality from complexity
Without gjalla, agent output quality degrades as task complexity increases. Simple features score around 6.4/10. Complex features drop to 5.2/10. The harder the task, the worse the output. The regression slope is -0.34 — a steady, predictable decline.
With gjalla, quality is nearly flat. The slope is -0.08. Whether the feature is simple or involves cross-cutting architectural changes across multiple services, quality stays in the 8–8.5 range.
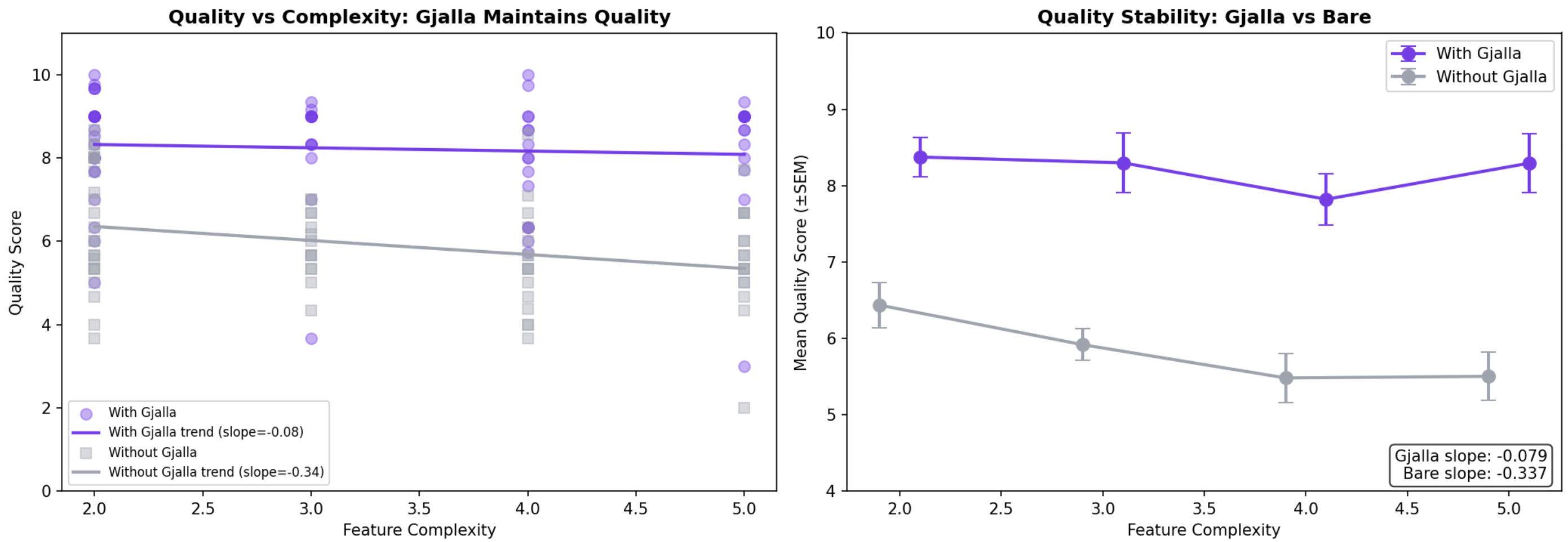
This means gjalla doesn’t just improve average quality — it eliminates the variance that makes AI-generated code unpredictable. The harder the task, the bigger the gap between agents with access to a curated source of truth and those without.
Put differently: without system context, complexity is a tax on quality. With it, it’s not.
This pattern also holds across codebase scale. Across our 8 test repositories (240K–536K lines), gjalla’s quality advantage correlates positively with codebase size (r=0.64). The largest codebases saw quality deltas of +3.0 to +3.4 points; the smallest saw +1.1 to +1.2. The bigger the system, the more that shared agent memory, a declarative source of truth, matters — because there’s more inherent complexity and more implicit rules for an agent to accidentally break.
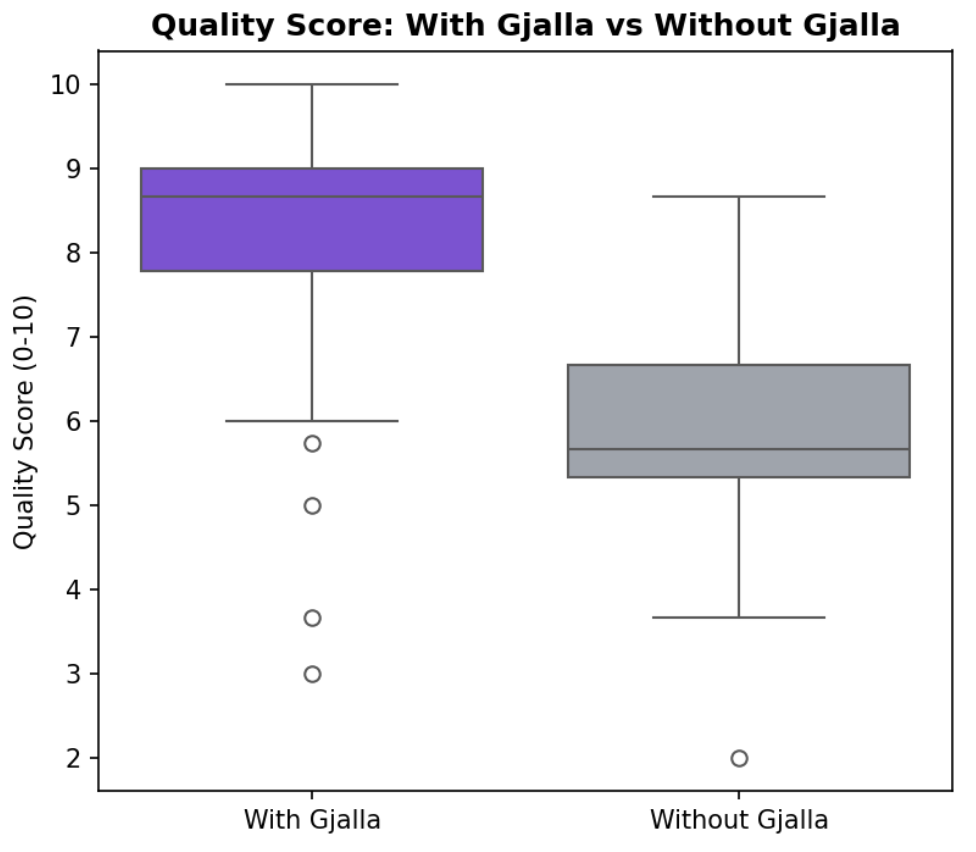
Quality: 23% improvement in quality
The headline result: gjalla-enabled coding agents produced higher quality output in 89% of comparisons, with an average improvement of +2.3 points on a 10-point scale.
The improvement wasn’t marginal. For context, most interventions studied in software engineering research show improvements 3–4x smaller than what we observed (Kitchenham et al., 2017). The result was statistically significant at p < 0.0001.
One of the largest advantages was in rule compliance — the degree to which code follows project-specific rules and constraints. Agents using gjalla scored 8.5/10 vs. 4.6/10… nearly double. This is the dimension most invisible to agents operating without context: they can’t follow rules they don’t know about, and those compliance details are left to human reviewers to catch.
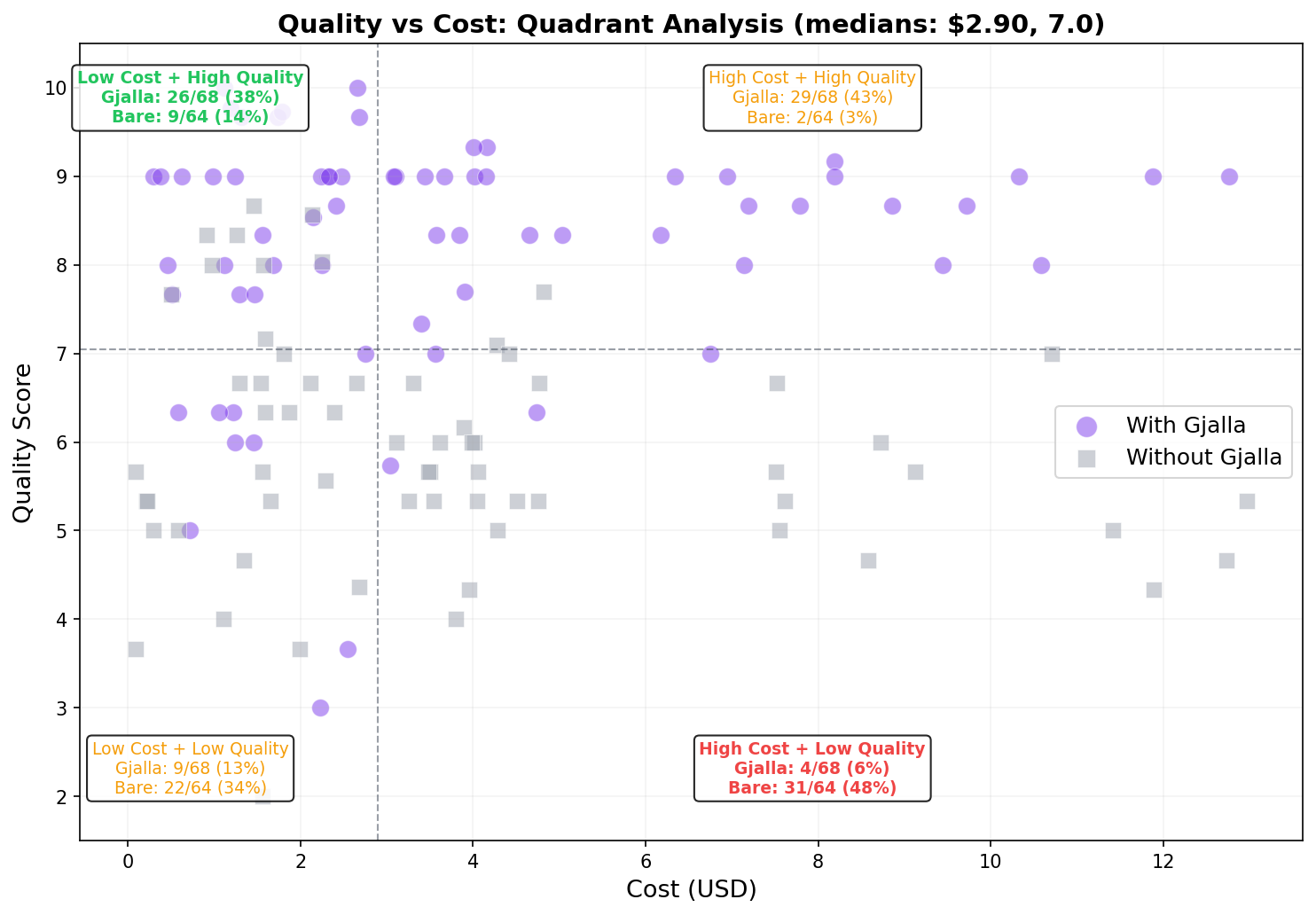
Efficiency: shared system context is not overhead
If I told you that to add a shared source of truth you’d need to add MCP calls, you’d probably say that likely adds time, would increase cost because of added context tokens, and you may be skeptical about the benefits.
What we found surprised us too: gjalla-enabled agents were faster in 61% of comparisons. When faster, median time savings were 31%. They were cheaper in 53% of comparisons. When cheaper, median cost savings were 22%.
In 50% of all comparisons, gjalla was simultaneously faster, cheaper, and better quality — a triple win.
The quality-cost distribution makes this concrete. When we plot every run by cost and quality score, 48% of baseline runs land in the worst quadrant — high cost, low quality. Only 6% of gjalla-enabled runs end up there. Conversely, 81% of gjalla-enabled runs produce high-quality output, compared to 17% for baseline.
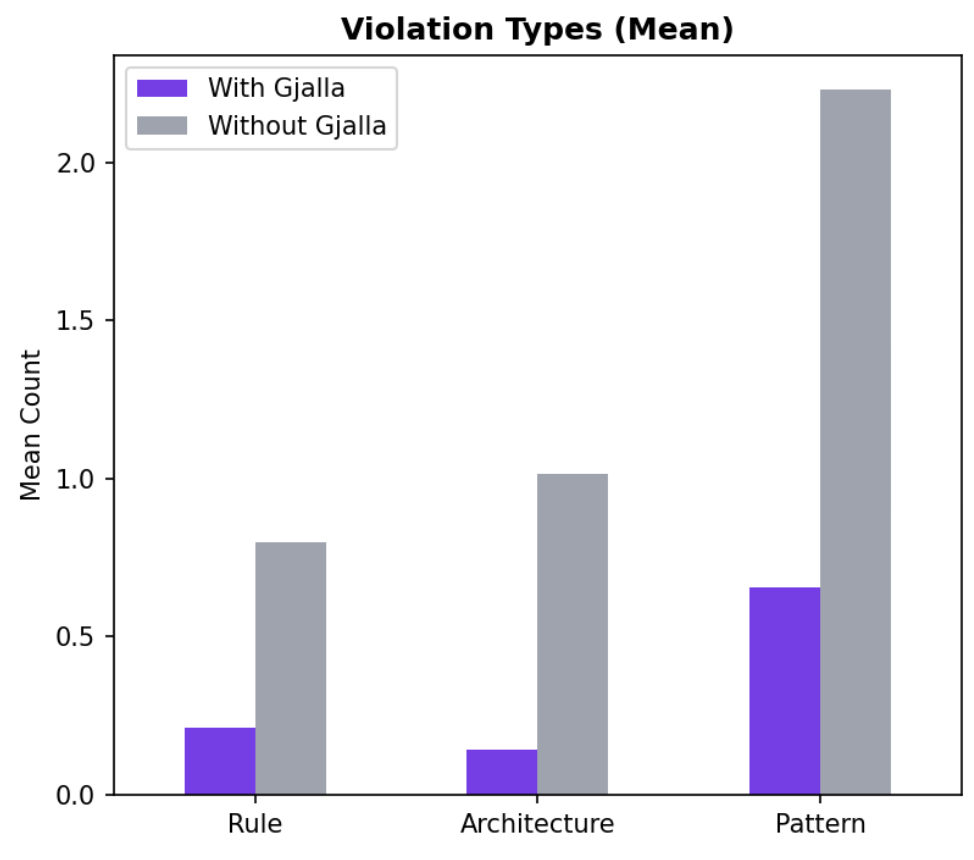
Violations: dramatically reduced
Beyond the aggregate quality score, we tracked specific violation types: rule violations, architecture violations, and pattern violations.
gjalla-enabled agents showed dramatic reductions across all three categories. Architecture violations (where implementations do not match the pre-existing architecture patterns) saw the biggest improvement.
Critically, violations grow with complexity for baseline agents but stay flat when agents have access to gjalla. This reinforces the core finding: a declarative source of truth neutralizes the complexity penalty.
Code hygiene: what gjalla catches before review
We also had the reviewer look for structural code quality issues… the types of issues that wouldn’t show up in broken tests but may cause problems down the line. (The things your senior engineers would catch in PR review!)
gjalla-enabled agents nearly eliminated such violations:
- Parallel abstractions (reinventing an existing service or type): -86%
- Misplaced files (code in the wrong directory or module): -95%
- Dependency direction violations (breaking the project’s dependency graph): -83%
- Changed files without tests: -44%
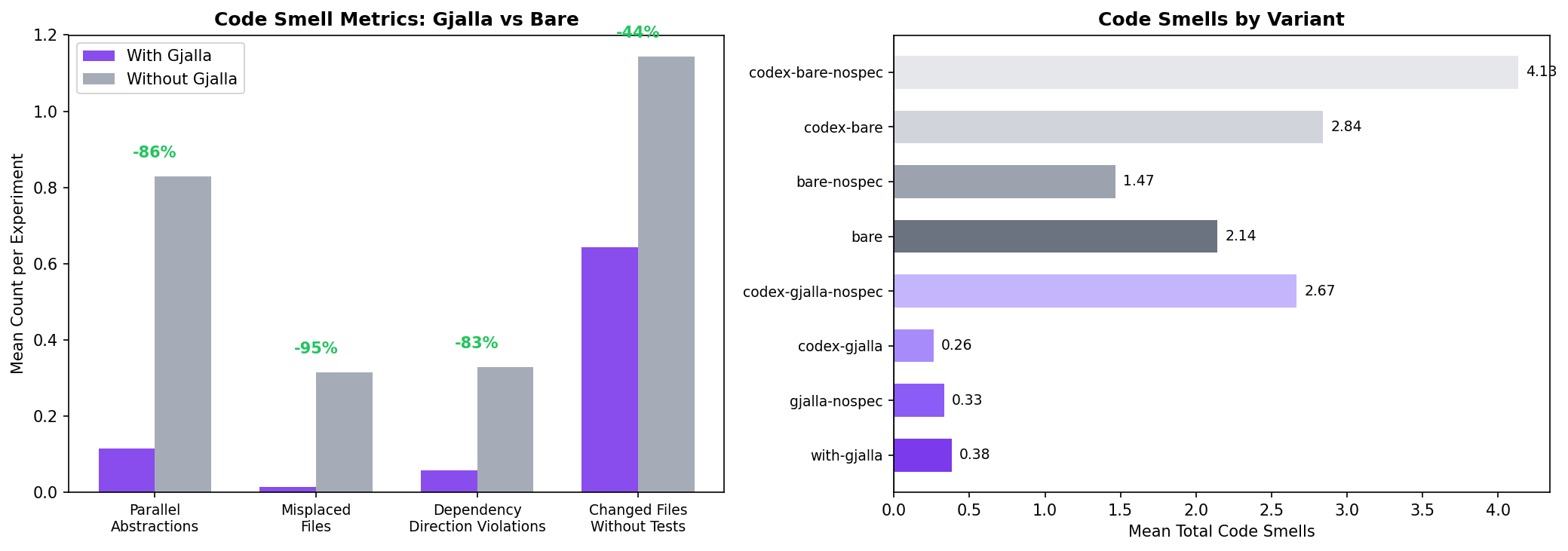
This matters because as AI-generated code volume grows, the review burden becomes the bottleneck. If every AI-generated PR requires a senior engineer to check whether the agent respected domain boundaries or reused existing abstractions, velocity gains evaporate. gjalla shifts that burden from human reviewers to the spec — catching structural problems before they reach the PR.
The compounding effect: gjalla gets better over time
gjalla’s source of truth is continuously learning — each analysis refines the architecture spec, captures new decisions, and tightens constraints. This means well-tuned instances produce increasingly strong results over time.
The codebases that have been in gjalla the longest — our own — showed the strongest results. These instances have been learning continuously since we started building, and the effects were even more pronounced: agents with gjalla were 41–43% faster and 37–47% cheaper (vs. the study-wide medians of 31% and 22%). Governance scores reached 8–10/10 compared to 3–6/10 without, and architecture violations dropped to zero across both paired reviews.
The study results represent gjalla after initial analysis of each codebase — essentially a cold start. The longer gjalla learns your system, the wider the gap becomes.
What this means for teams shipping with AI
These results suggest something important about the AI coding adoption curve: the bottleneck isn’t model capability — it’s stateful, system-wide context. The infrastructure that delivers that context to agents at the point of implementation — a persistent source of truth for how the system should work — is what makes the difference.
Coding agents are already good enough to produce production-quality work, and they’re still getting better. We’ve seen this firsthand — coding agents made us faster, but the review and correction burden grew with them. With the right context and guardrails, production-readiness is no longer a bottleneck. Without it, agents make implicit architectural decisions, implement without knowledge of constraints, and introduce drift that humans would usually catch in code review. Code review that is not feasible at the scale that agents write code.
The pattern we’re seeing is analogous to what happened with infrastructure-as-code. Before Terraform, teams managed infrastructure imperatively. It worked at small scale but became unmanageable as systems grew. Terraform’s insight was that declaring expected state and letting automation converge toward it was more reliable than managing individual actions.
AI-assisted software development is at the same inflection point. Individual agents are capable. But without a declared expected state — architecture rules, constraints, patterns — their collective output drifts unpredictably. Before coding agents, that state lived in engineers’ heads. A senior dev knew which service owned authentication, why the team chose event sourcing, which modules shouldn’t depend on each other. That worked when humans wrote all the code. It doesn’t work when agents generate code at 10x the volume and don’t have access to any of that institutional knowledge.
That’s what we’re building at gjalla — a centralized, continuously-learning system of record for your architecture’s expected state. Agents query it before they write code. Quality becomes complexity-independent. Efficiency improves. And every decision is traceable back to the architecture that informed it.
If your team is shipping with AI coding tools and you’re seeing quality variance as tasks get more complex, we’d love to talk.